|
I am currently a researcher at Meituan Inc. My primary research interests encompass a broad range of topics, including large multimodal models, diffusion models, autonomous driving, embodied AI, object detection, domain adaptation, and more. Specifically, I am particularly interested in the application of large multimodal models and diffusion models to improve our daily lives. Home / Email / Github / Google Scholar |

|
|
|
|
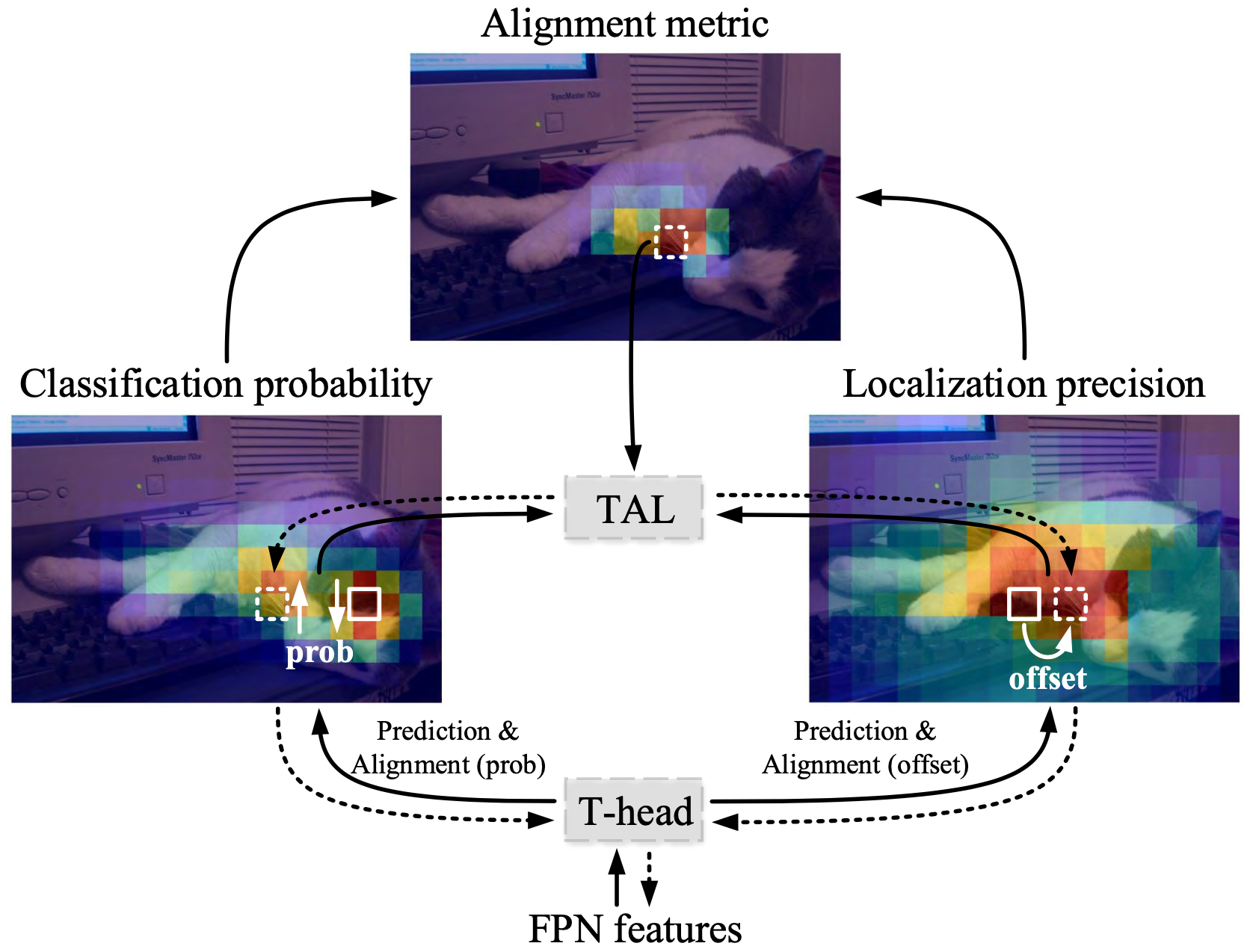
Chenjian Feng, Yujie Zhong, Yu Gao, Matthew R. Scott, Weilin Huang ICCV, 2021 (Oral) project page / arXiv We propose a Task-aligned One-stage Object Detection (TOOD) that explicitly aligns the classification and localization tasks in a learning-based manner. It is widely applied by YOLO series, such as PP-YOLOE, YOLOv6, YOLOv8, YOLOv10, YOLO-World. |
|
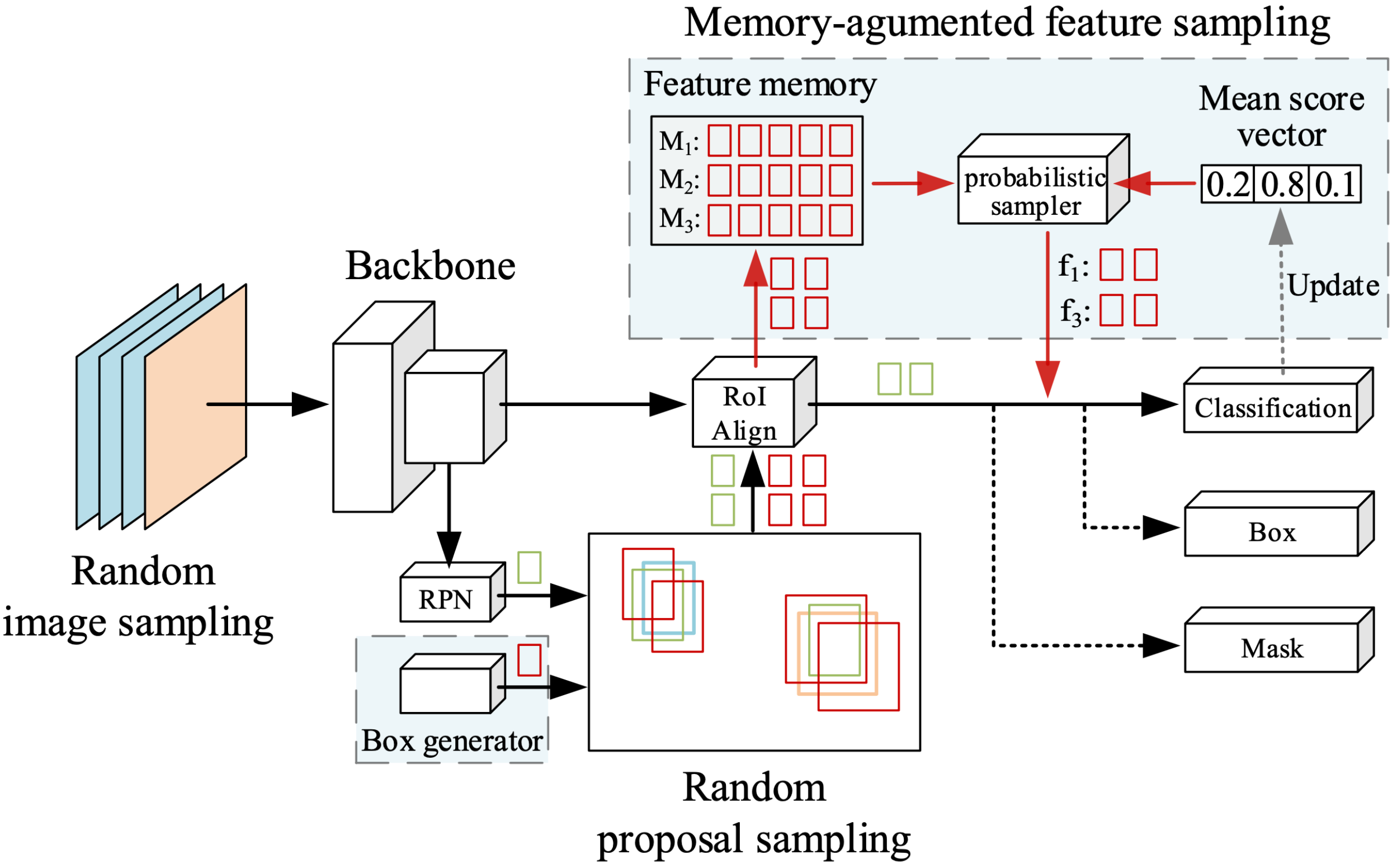
Chenjian Feng, Yujie Zhong, Weilin Huang ICCV, 2021 project page / arXiv We balance the classification of the long-tailed detector via an Equilibrium Loss (EBL) and a Memory-augmented Feature Sampling (MFS) method. |
|
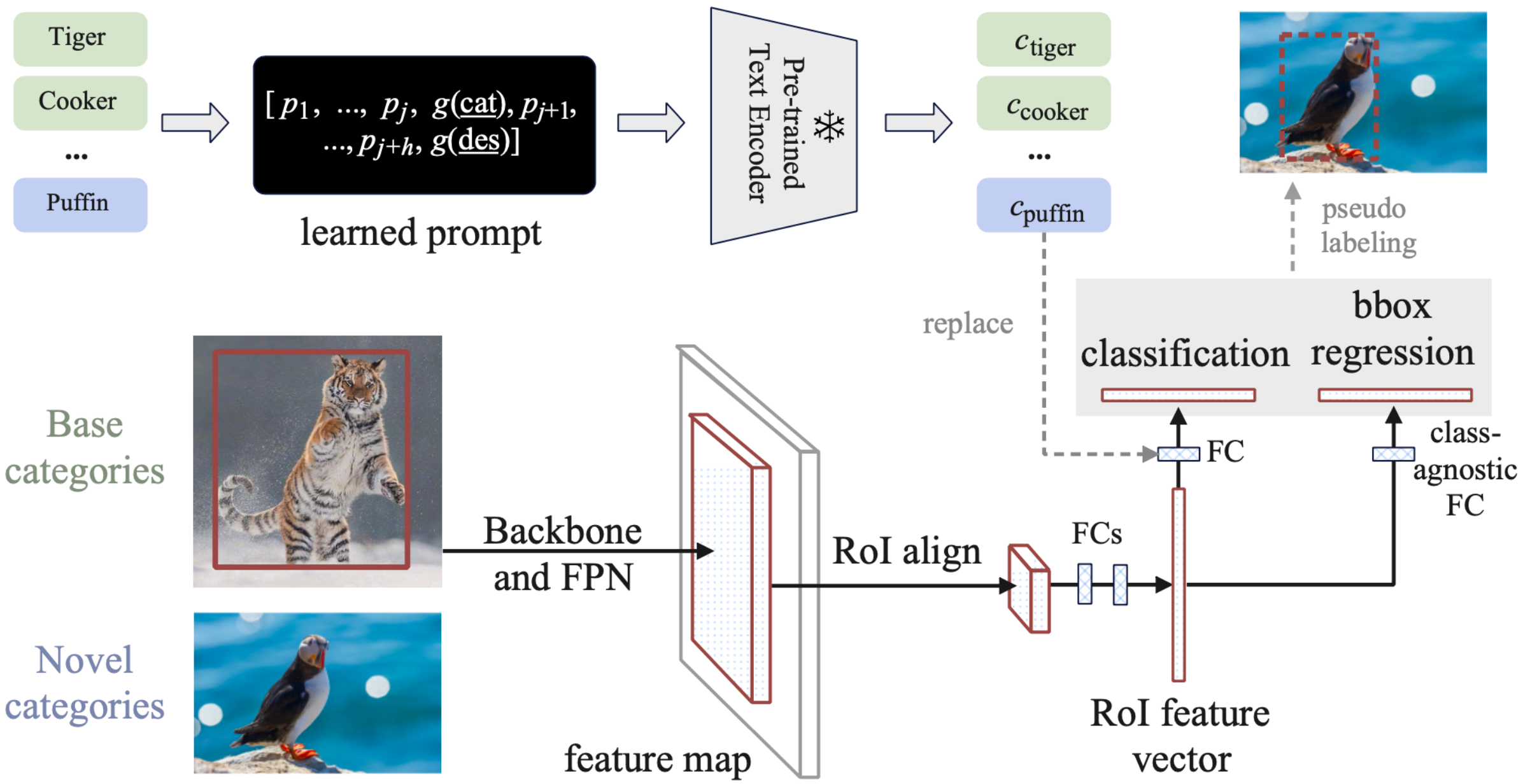
Chenjian Feng, Yujie Zhong, Zequn Jie, Xiangxiang Chu, Haibing Ren, Xiaolin Wei, Weidi Xie, Lin Ma ECCV, 2022 project page / arXiv We propose an open-vocabulary object detector PromptDet, which is able to detect novel categories without any manual annotations. |
|
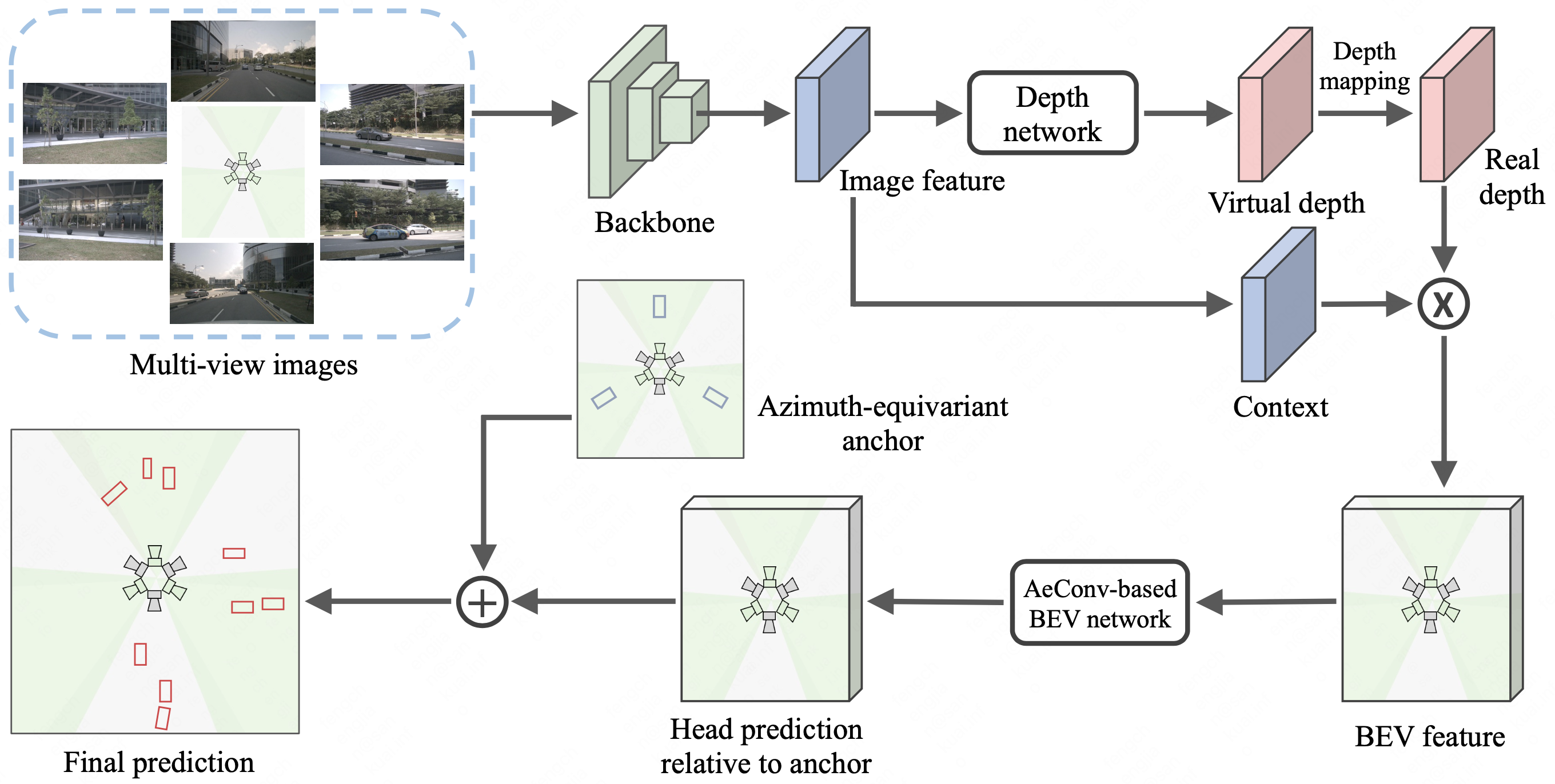
Chenjian Feng, Zequn Jie, Yujie Zhong, Xiangxiang Chu, Lin Ma CVPR, 2023 project page / arXiv We propose an Azimuth-equivariant Detector (AeDet) that is able to perform azimuth-invariant multi-view 3D object detection. |
|
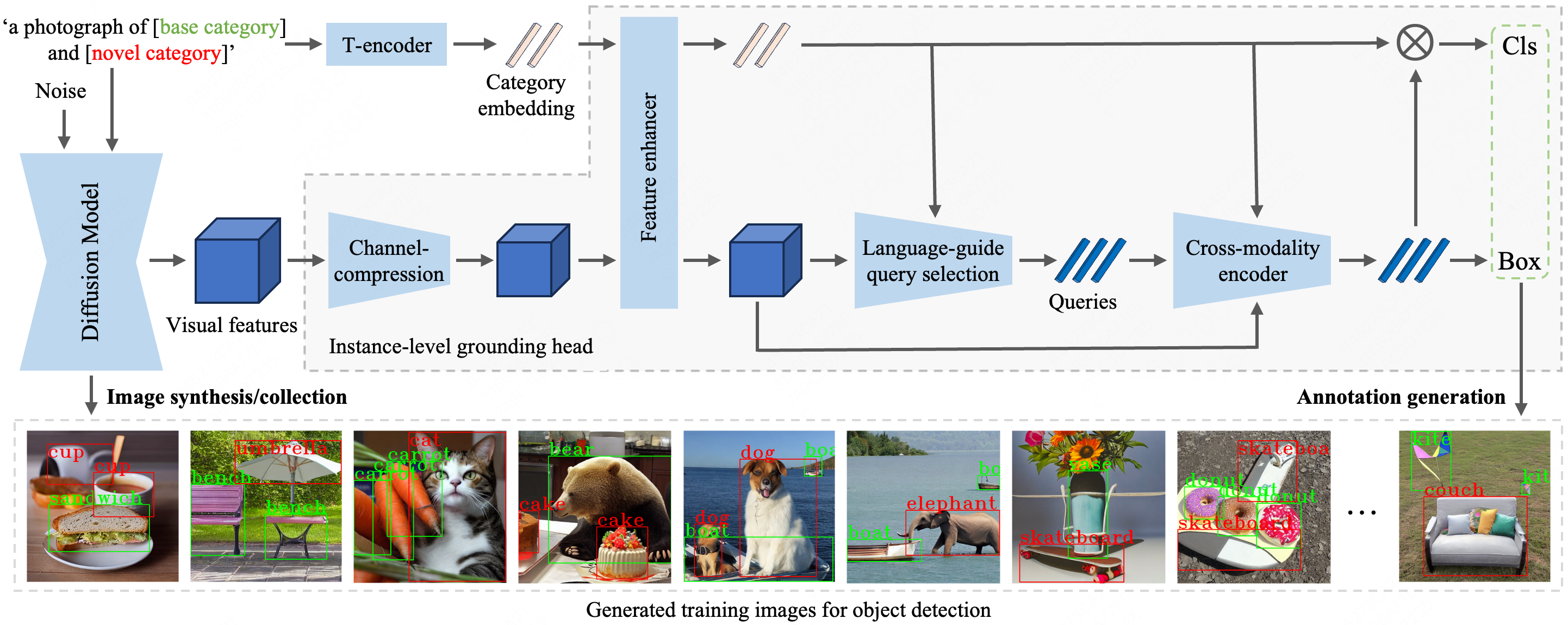
Chenjian Feng, Yujie Zhong, Zequn Jie, Weidi Xie, Lin Ma CVPR, 2024 project page / arXiv We introduce a novel paradigm to enhance the ability of object detector by training on synthetic dataset generated from diffusion models. |
|
|
|
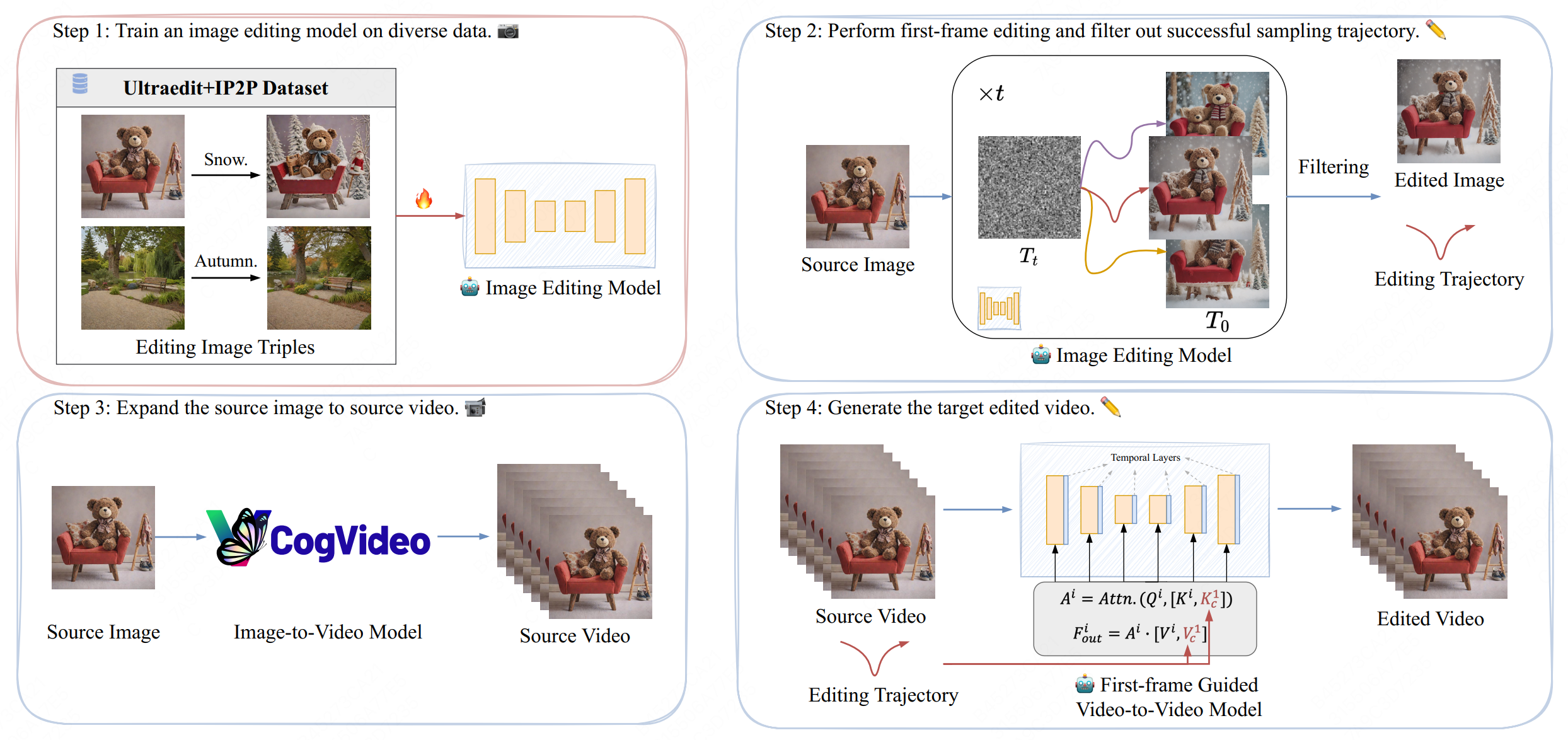
Chi Zhang*, Chengjian Feng*, Feng Yan, Qiming Zhang, Mingjin Zhang, Yujie Zhong, Jing Zhang, Lin Ma (*Equal contribution) Preprint, 2025 project page / arXiv We present InstructVEdit, a holistic approach for instructional video editing that includes a robust dataset curation workflow, two architectural model improvements, and an iterative refinement strategy. |
|
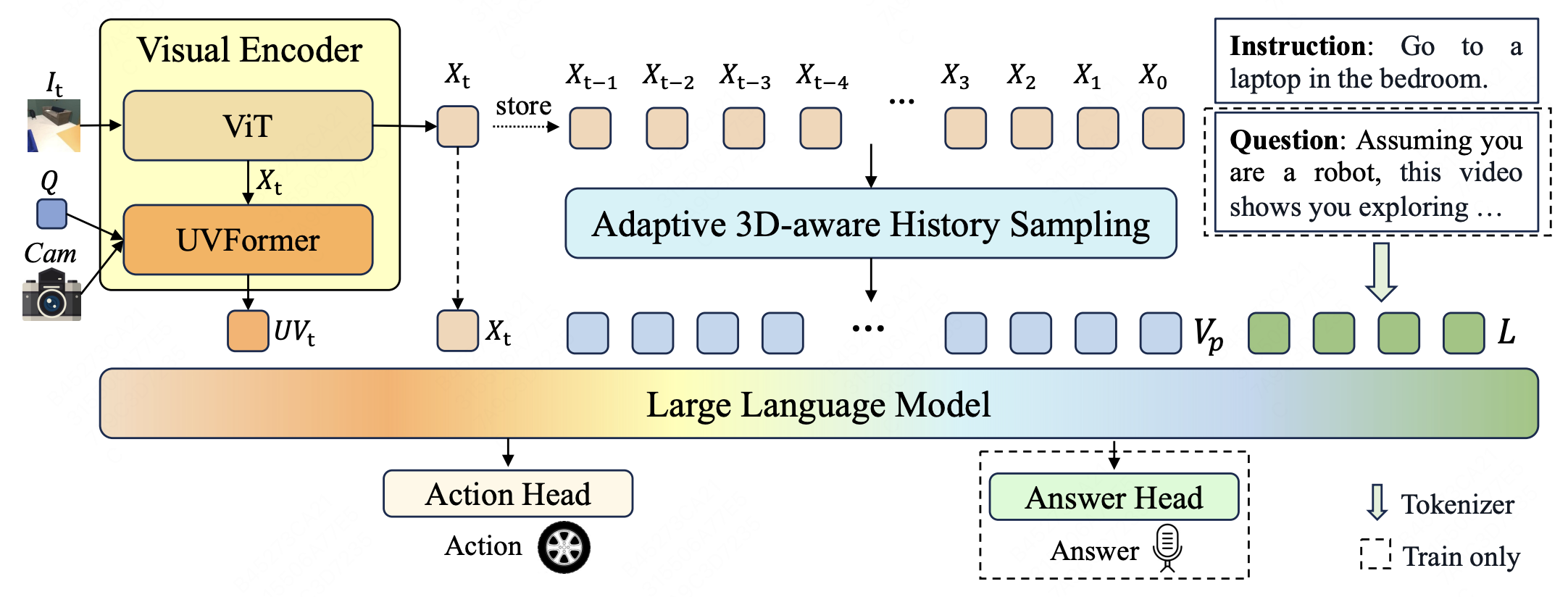
Yufeng Zhong*, Chengjian Feng*, Feng Yan, Fanfan Liu, Liming Zheng, Lin Ma (*Equal contribution) Preprint, 2025 project page / arXiv we introduce P3Nav, a unified framework that integrates Perception, Planning, and Prediction capabilities through Multitask Collaboration on navigation and embodied question answering tasks. |
|
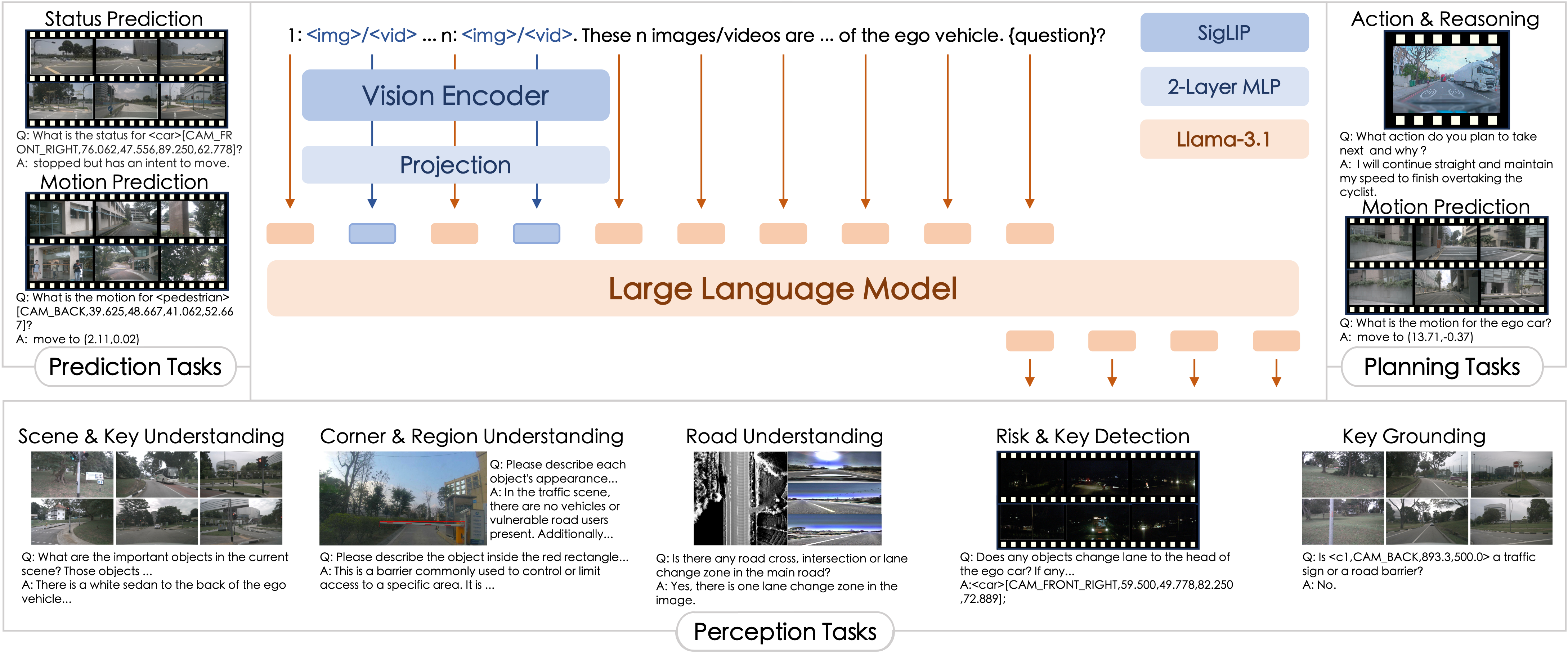
Zhijian Huang*, Chengjian Feng*, Feng Yan, Baihui Xiao, Zequn Jie, Yujie Zhong, Xiaodan Liang, Lin Ma (*Equal contribution) Preprint, 2024 project page / arXiv We propose a novel all-in-one large multimodal model, DriveMM, robustly equipped with the general capabilities and the generalization ability. |

|
Feng Yan, Fanfan Liu, Liming Zheng, Yufeng Zhong, Yiyang Huang, Zechao Guan, Chengjian Feng, Lin Ma Preprint, 2024 project page / arXiv We propose a multimodal robotic manipulation model, RoboMM, along with a comprehensive dataset, RoboData. |
|
|
Chenjian Feng, Yujie Zhong, Zequn Jie, Weidi Xie, Lin Ma CVPR, 2024 project page / arXiv We introduce a novel paradigm to enhance the ability of object detector by training on synthetic dataset generated from diffusion models. |
|
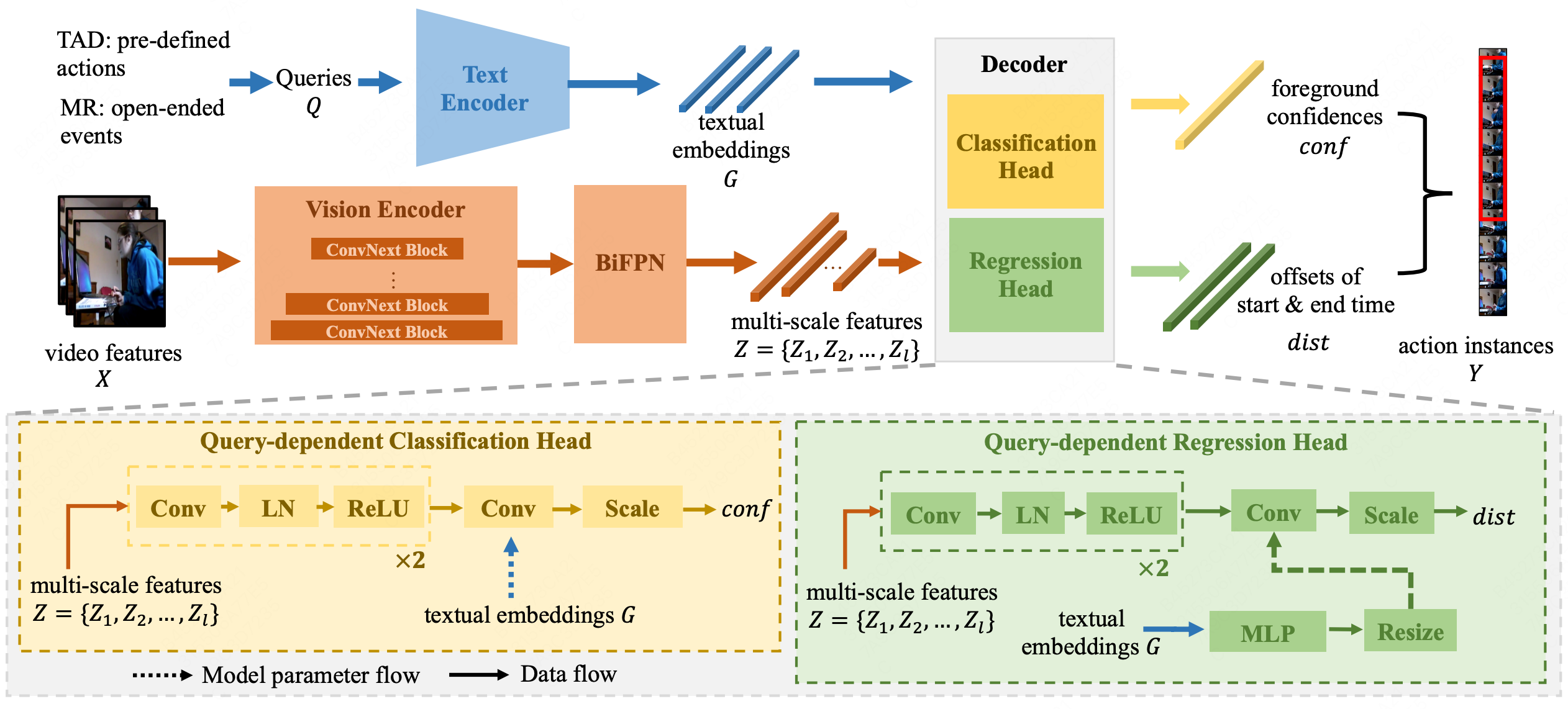
Yingsen Zeng, Yujie Zhong, Chenjian Feng, Lin Ma ECCV, 2024 project page / arXiv We propose a unified architecture, UniMD, for both TAD and MR, and explore a task fusion learning scheme to enhance the mutual benefits between the two tasks. |
|
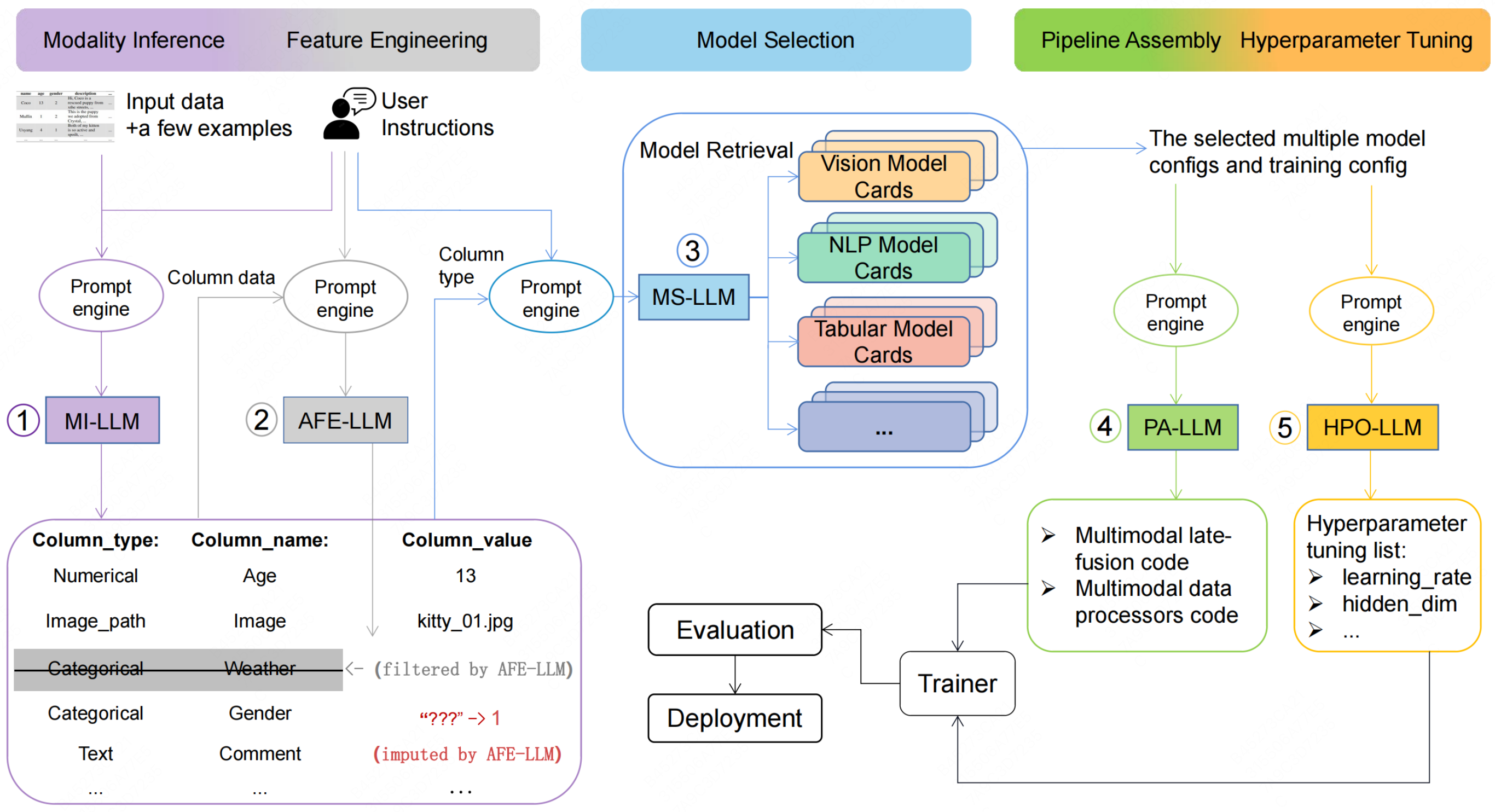
Daqin Luo, Chenjian Feng, Yuxuan Nong, Yiqing Shen ACMMM, 2024 project page / arXiv We introduce AutoM3L, an innovative Automated Multimodal Machine Learning framework that leverages LLMs as controllers to automatically construct multimodal training pipelines. |
|
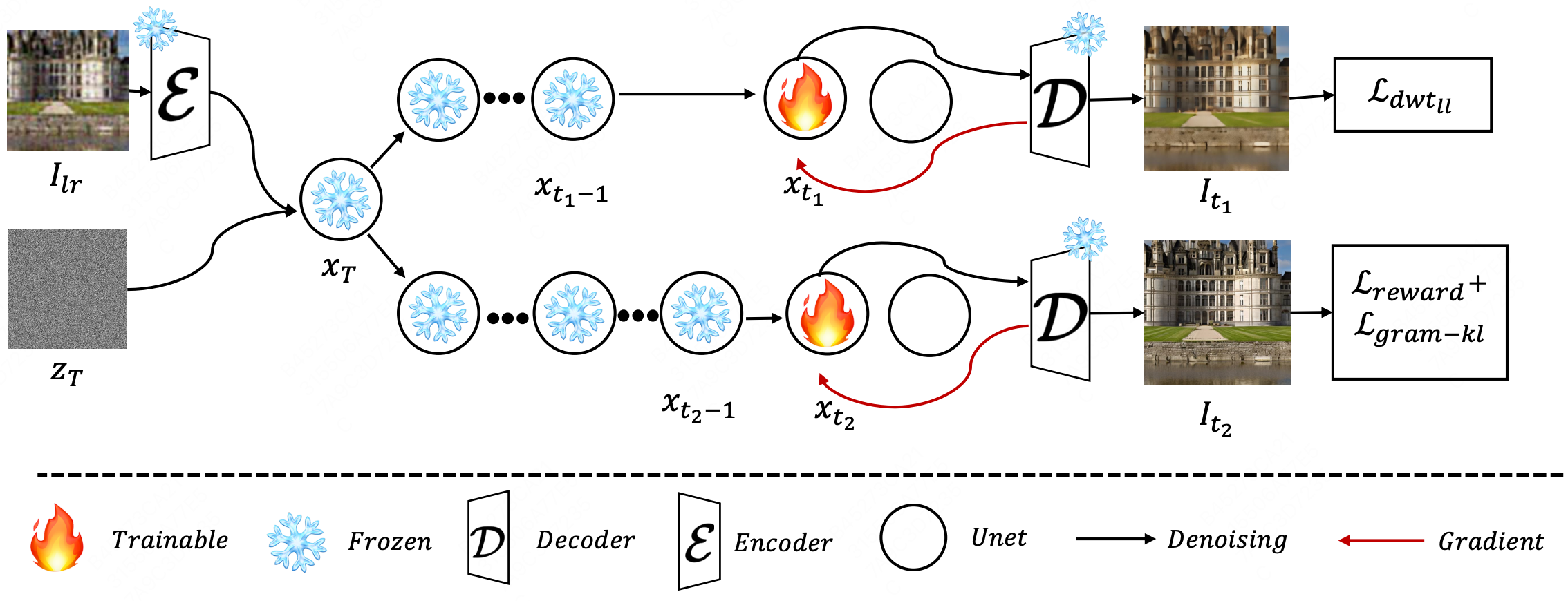
Xiaopeng Sun, Qinwei Lin, Yu Gao, Yujie Zhong, Chengjian Feng, Dengjie Li, Zheng Zhao, Jie Hu, Lin Ma Preprint, 2024 project page / arXiv We propose a multimodal robotic manipulation model, RoboMM, along with a comprehensive dataset, RoboData. |
|
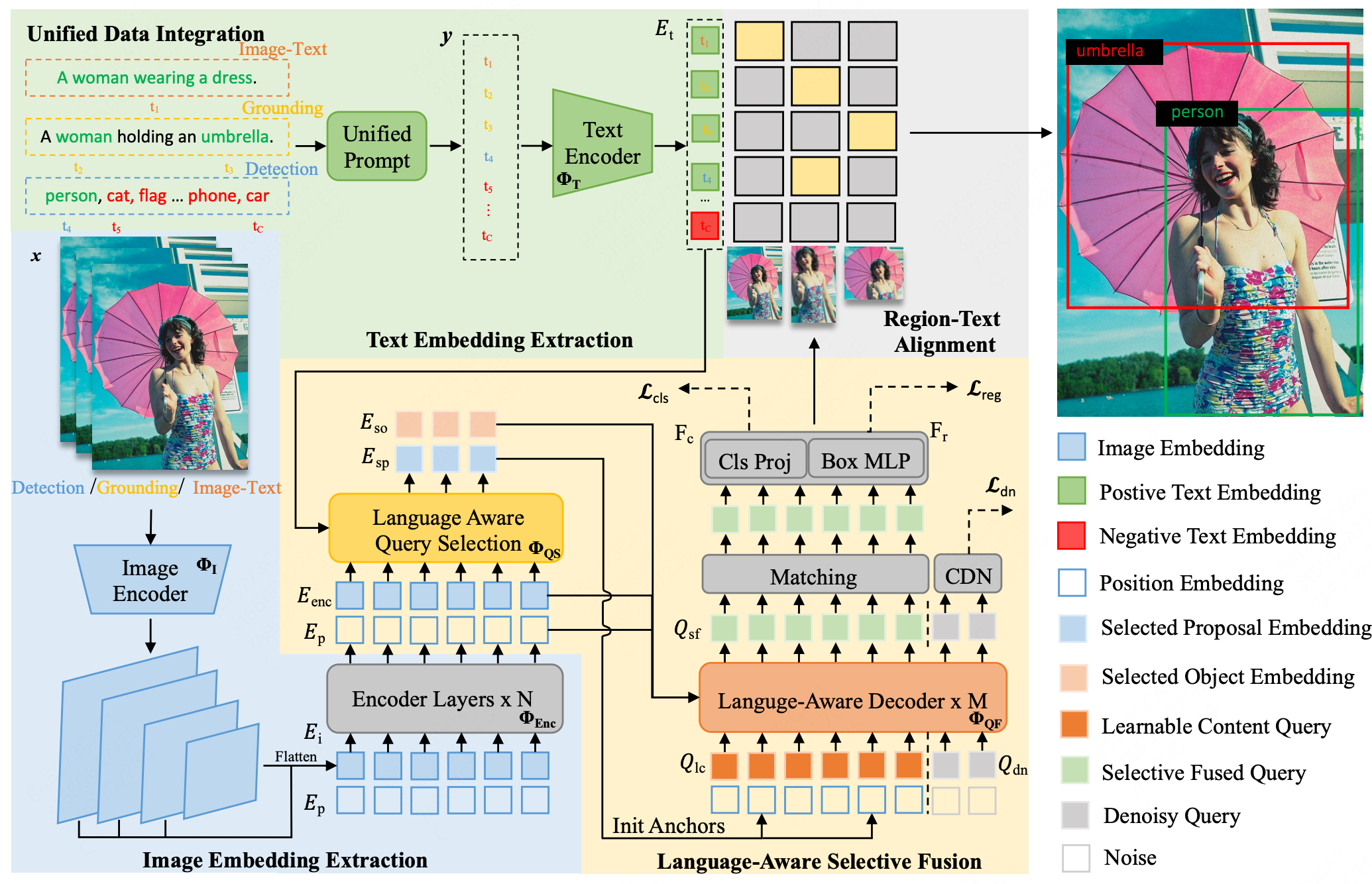
Hao Wang, Pengzhen Ren, Zequn Jie, Xiao Dong, Chenjian Feng, Yinlong Qian, Lin Ma, Dongmei Jiang,, Yaowei Wang, Xiangyuan Lan, Xiaodan Liang Preprint, 2024 project page / arXiv We propose a novel unified open-vocabulary detection method called OV-DINO, which is pre-trained on diverse large-scale datasets with language-aware selective fusion in a unified framework. |
|
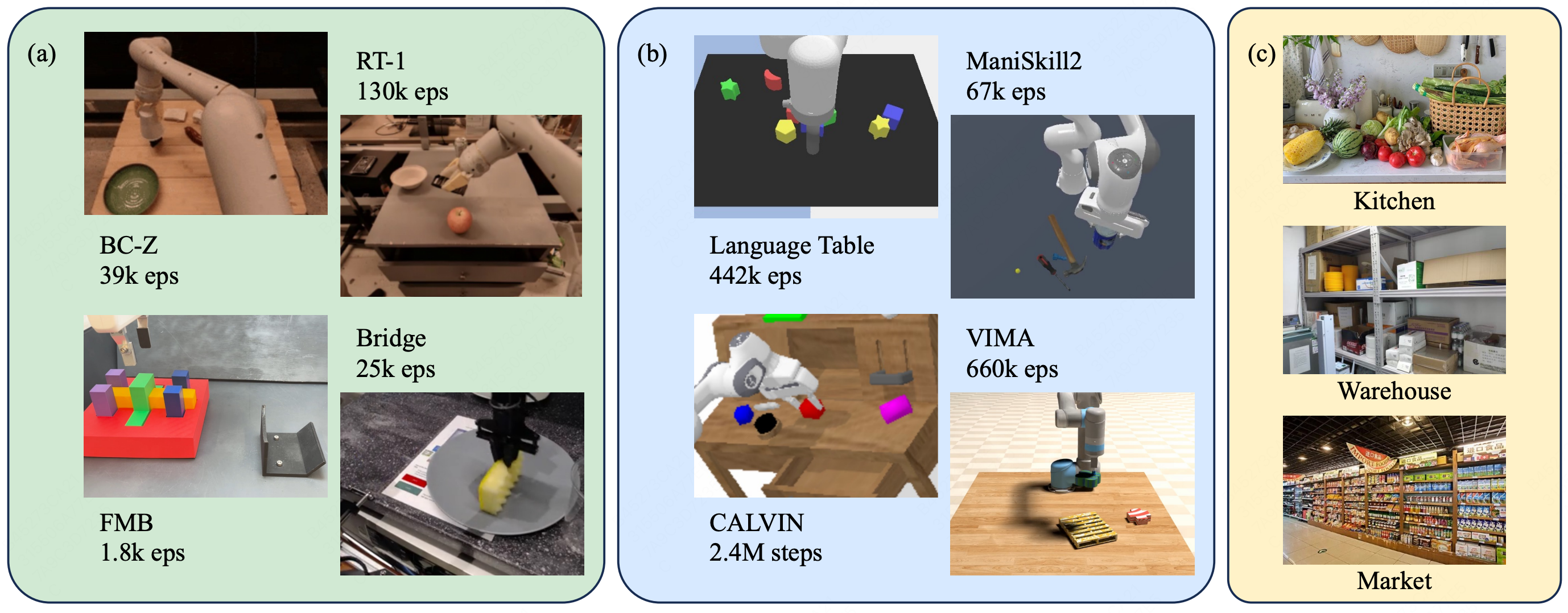
Liming Zheng, Feng Yan, Fanfan Liu, Chenjian Feng, Zhuoliang Kang, Lin Ma, Preprint, 2024 project page / arXiv We introduces RoboCAS, the first benchmark specifically designed for complex object arrangement scenarios in robotic manipulation. |
|
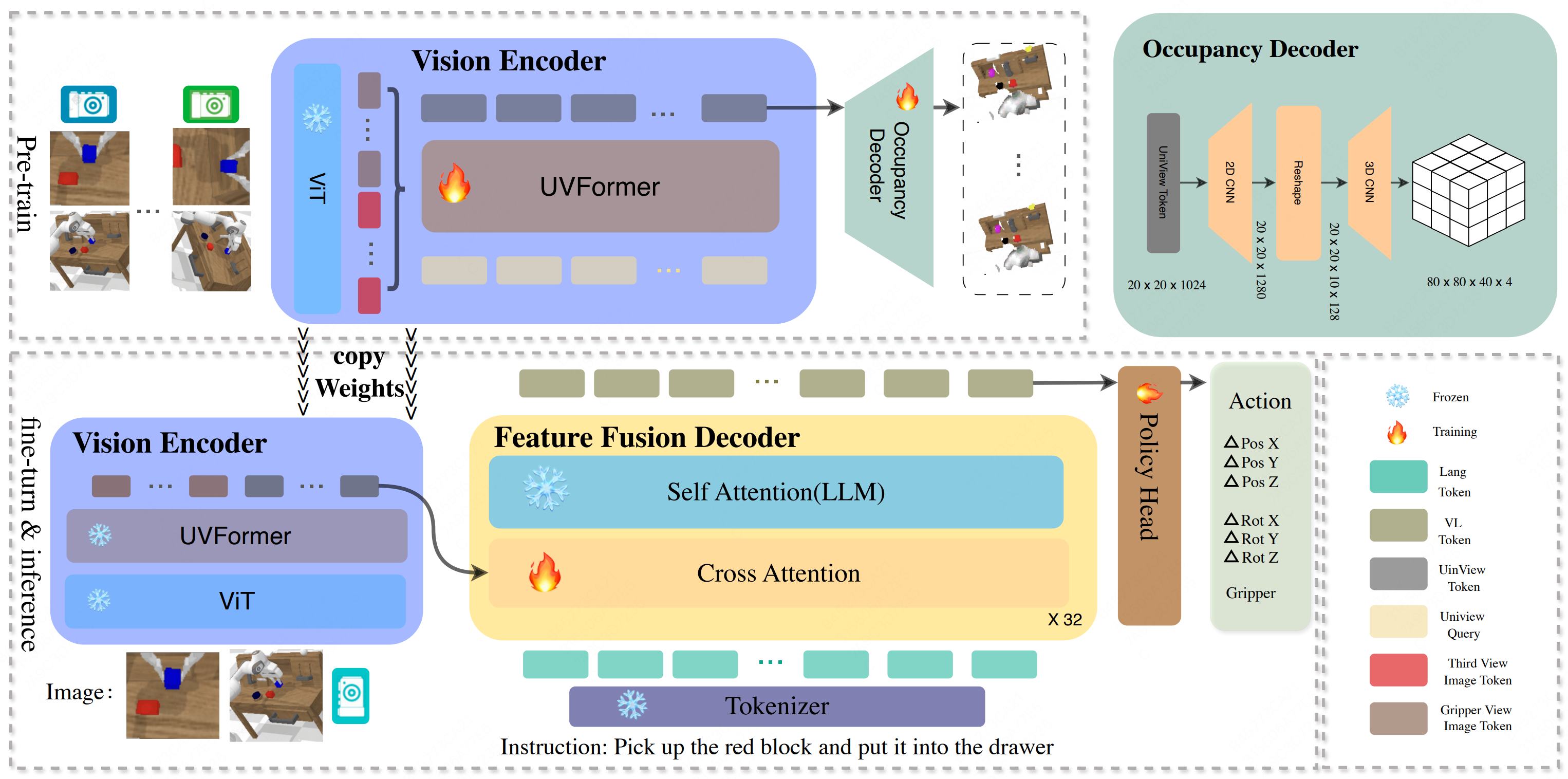
Fanfan Liu, Feng Yan, Liming Zheng, Chenjian Feng, Yiyang Huang, Lin Ma, Preprint, 2024 project page / arXiv We propose RoboUniView, an innovative approach that decouples visual feature extraction from action learning by a unified view representation. |
|
|
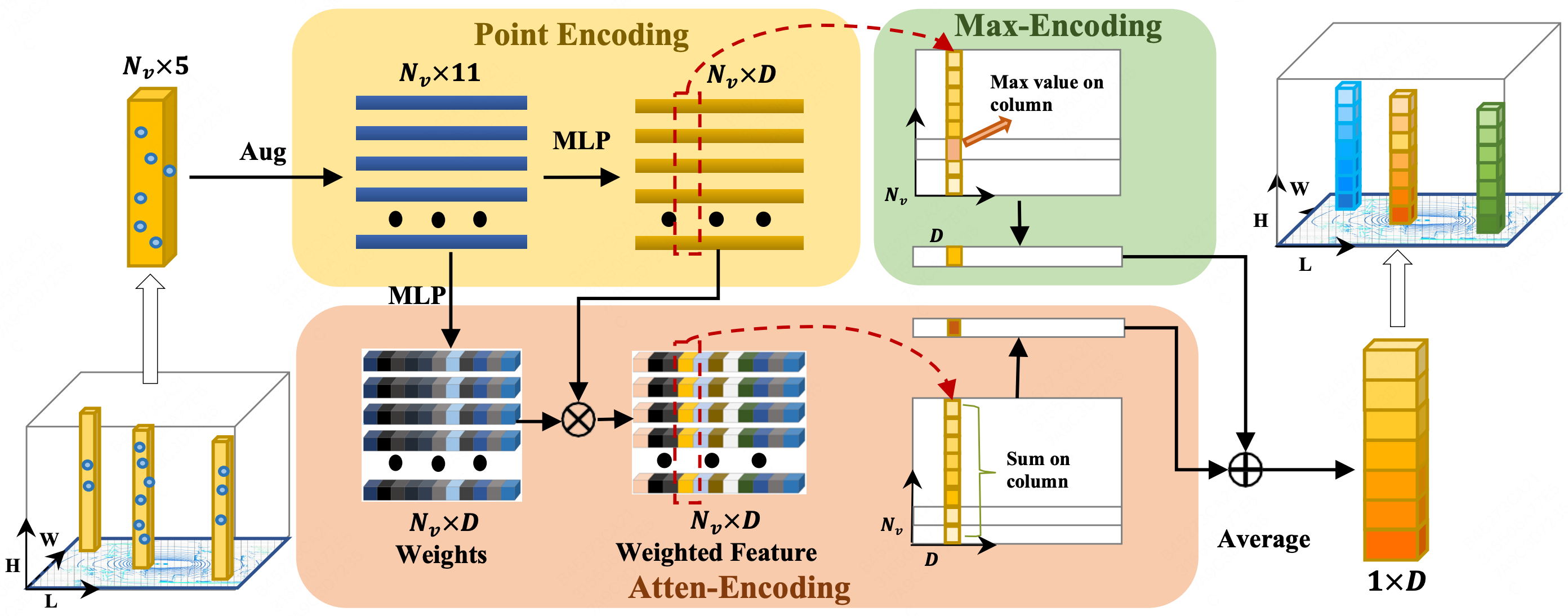
Chenjian Feng, Zequn Jie, Yujie Zhong, Xiangxiang Chu, Lin Ma CVPR, 2023 project page / arXiv We propose an Azimuth-equivariant Detector (AeDet) that is able to perform azimuth-invariant multi-view 3D object detection. |
|
Sifan Zhou, Zhi Tian, Xiangxiang Chu, Xinyu Zhang, Bo Zhang, Xiaobo Lu, Chenjian Feng, Zequn Jie, Patrick Yin Chiang, Lin Ma Preprint, 2023 project page / arXiv We devise a deployment-friendly pillar-based 3D detector, termed FastPillars, to tackle the challenge of efficient 3D object detection from an industry perspective. |
|
|
Chenjian Feng, Yujie Zhong, Zequn Jie, Xiangxiang Chu, Haibing Ren, Xiaolin Wei, Weidi Xie, Lin Ma ECCV, 2022 project page / arXiv We propose an open-vocabulary object detector PromptDet, which is able to detect novel categories without any manual annotations. |
|
|
Chenjian Feng, Yujie Zhong, Yu Gao, Matthew R. Scott, Weilin Huang ICCV, 2021 (Oral) project page / arXiv We propose a Task-aligned One-stage Object Detection (TOOD) that explicitly aligns the classification and localization tasks in a learning-based manner. |
|
|
Chenjian Feng, Yujie Zhong, Weilin Huang ICCV, 2021 project page / arXiv We balance the classification of the long-tailed detector via an Equilibrium Loss (EBL) and a Memory-augmented Feature Sampling (MFS) method. |
|
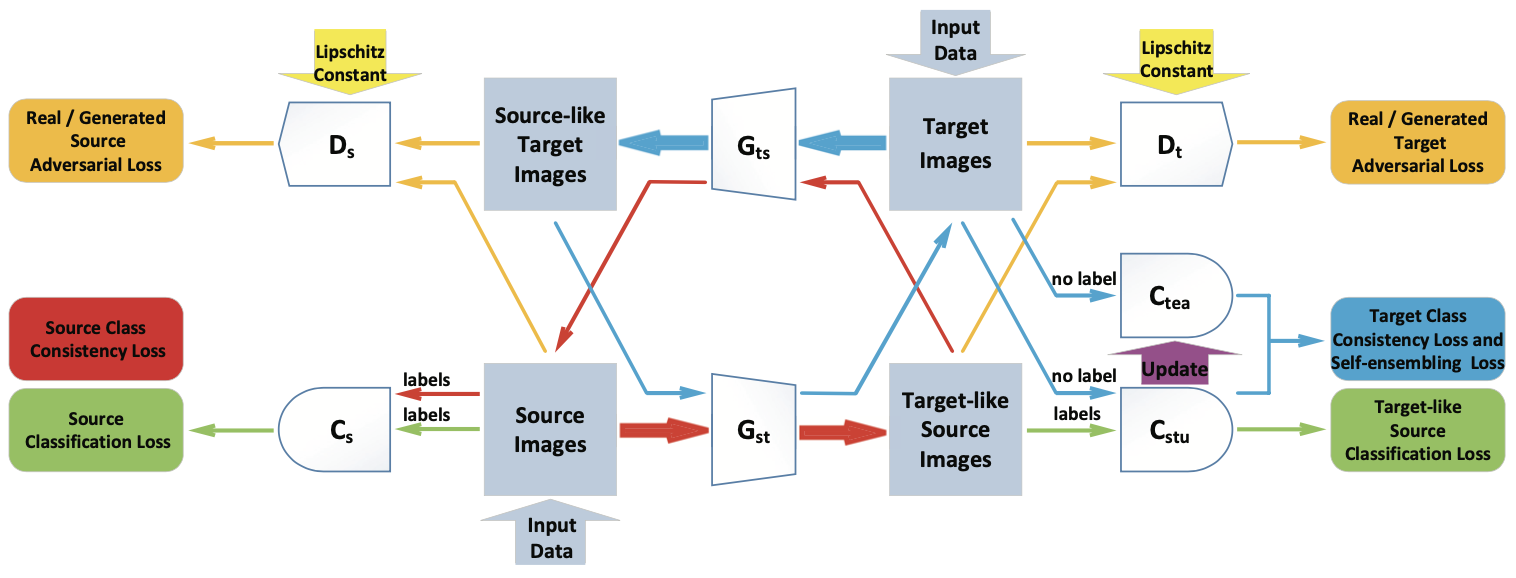
Chenjian Feng, Zhaoshui He, Jiawei Wang, Qinzhuang Lin, Zhouping Zhu, Jun Lv, Shengli Xie Neurocomputing, 2020 We propose a powerful model for unsupervised domain adaptation by introducing Mean Teacher as a target classifier of SBADA-GAN. |
|
Template gratefully stolen from here. |