|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
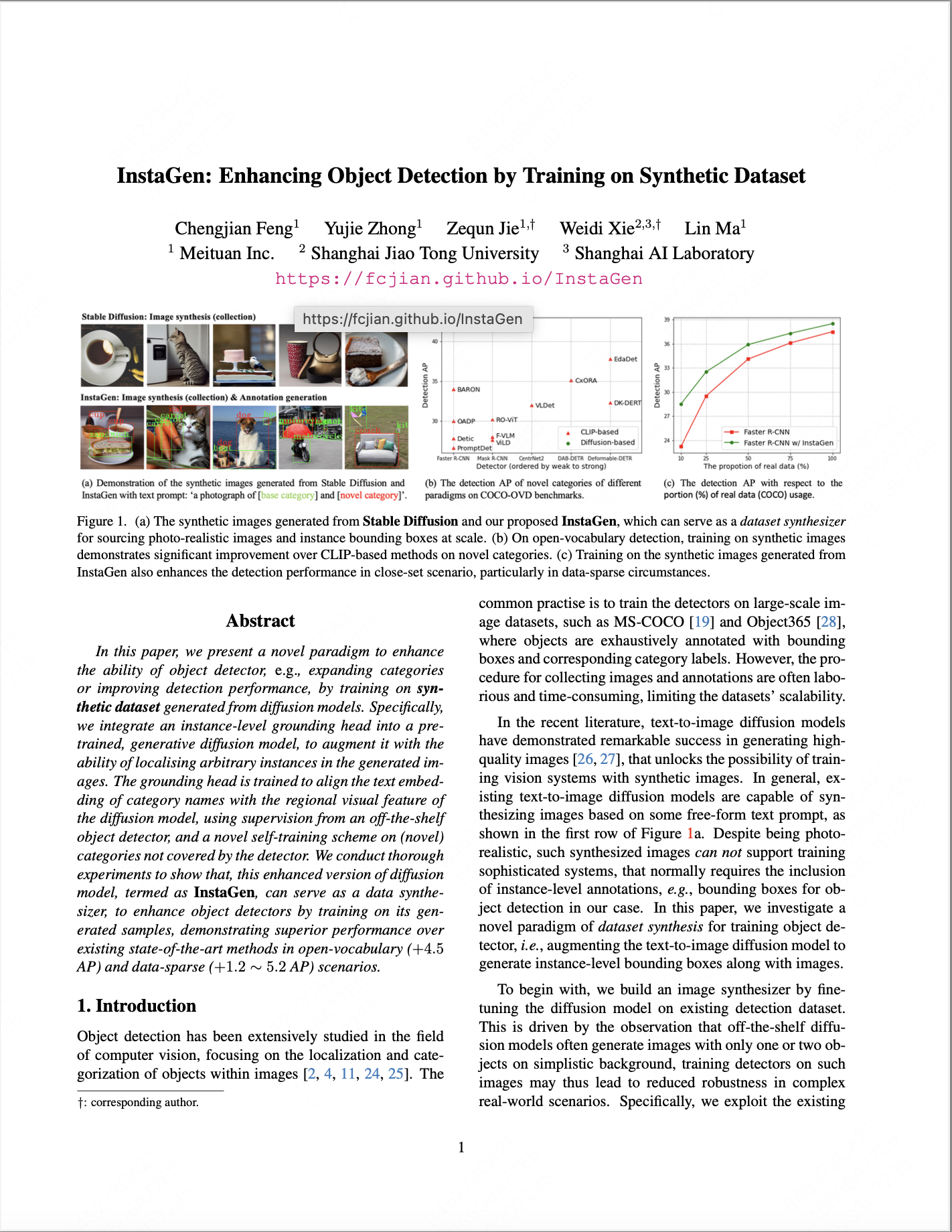
| In this paper, we introduce a novel paradigm to enhance the ability of object detector, e.g., expanding categories or improving detection performance, by training on synthetic dataset generated from diffusion models. Specifically, we integrate an instance-level grounding head into a pre-trained, generative diffusion model, to augment it with the ability of localising arbitrary instances in the generated images. The grounding head is trained to align the text embedding of category names with the regional visual feature of the diffusion model, using supervision from an off-the-shelf object detector, and a novel self-training scheme on (novel) categories not covered by the detector. This enhanced version of diffusion model, termed as InstaGen, can serve as a data synthesizer for object detection. We conduct thorough experiments to show that, object detector can be enhanced while training on the synthetic dataset from InstaGen, demonstrating superior performance over existing state-of-the-art methods in open-vocabulary (+4.5 AP) and data-sparse (+1.2 ∼ 5.2 AP) scenarios. |
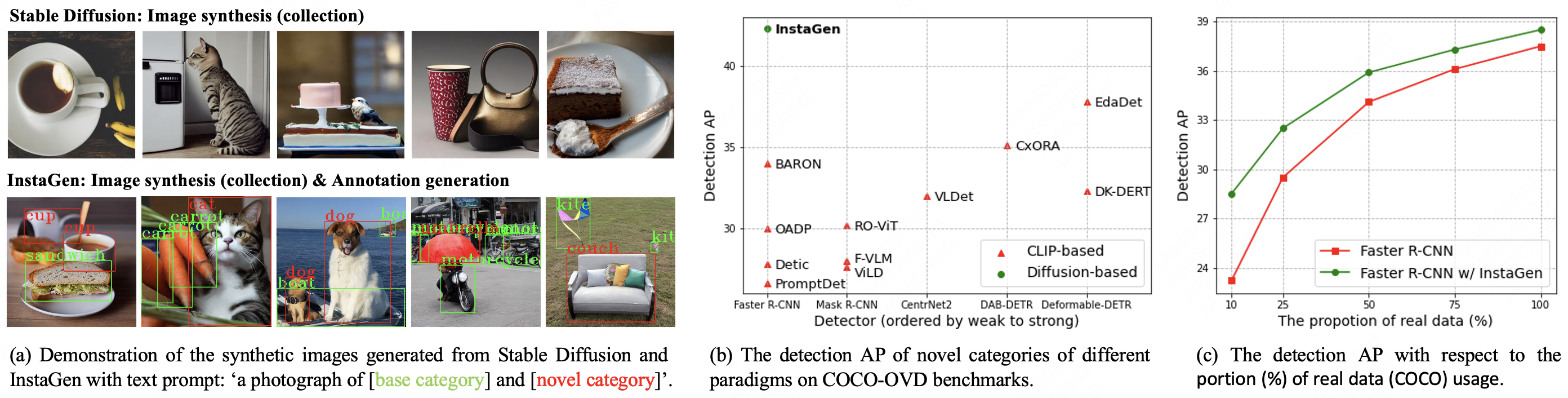
| To simultaneously generate the images and object bounding boxes, we propose a novel instance-level grounding module, which aligns the text embedding of category name with the regional visual features from image synthesizer, and infers the coordinates for the objects in synthetic images. To further improve the alignment towards objects of arbitrary category, we adopt self-training to tune the grounding module on object categories not existing in the real dataset. As a result, the proposed model, termed as InstaGen, can automatically generate images along with bounding boxes for object instances, and construct synthetic dataset at scale, leading to improved ability when training detectors on it. |
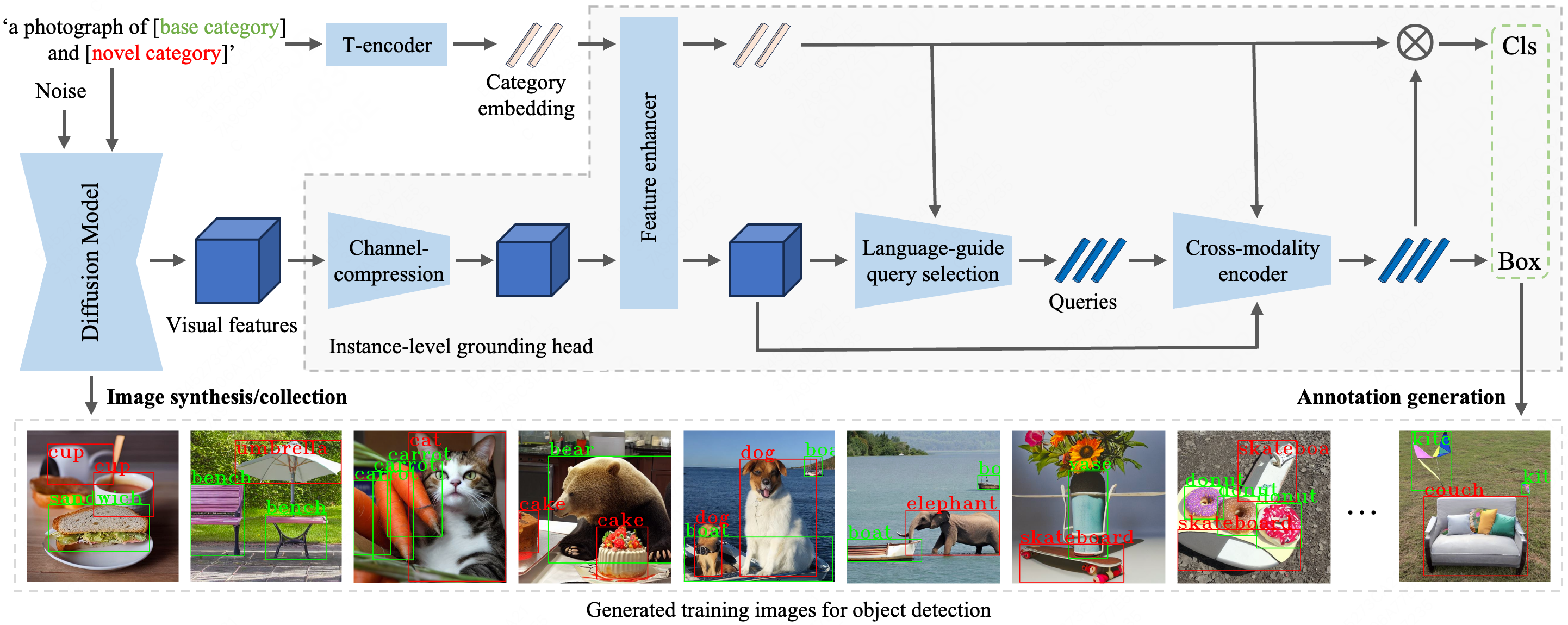 |
| Visualization of the synthetic dataset generated by our InstaGen. The bounding-boxes with green denote the objects from base categories, while the ones with red denote the objects from novel categories. |
 |
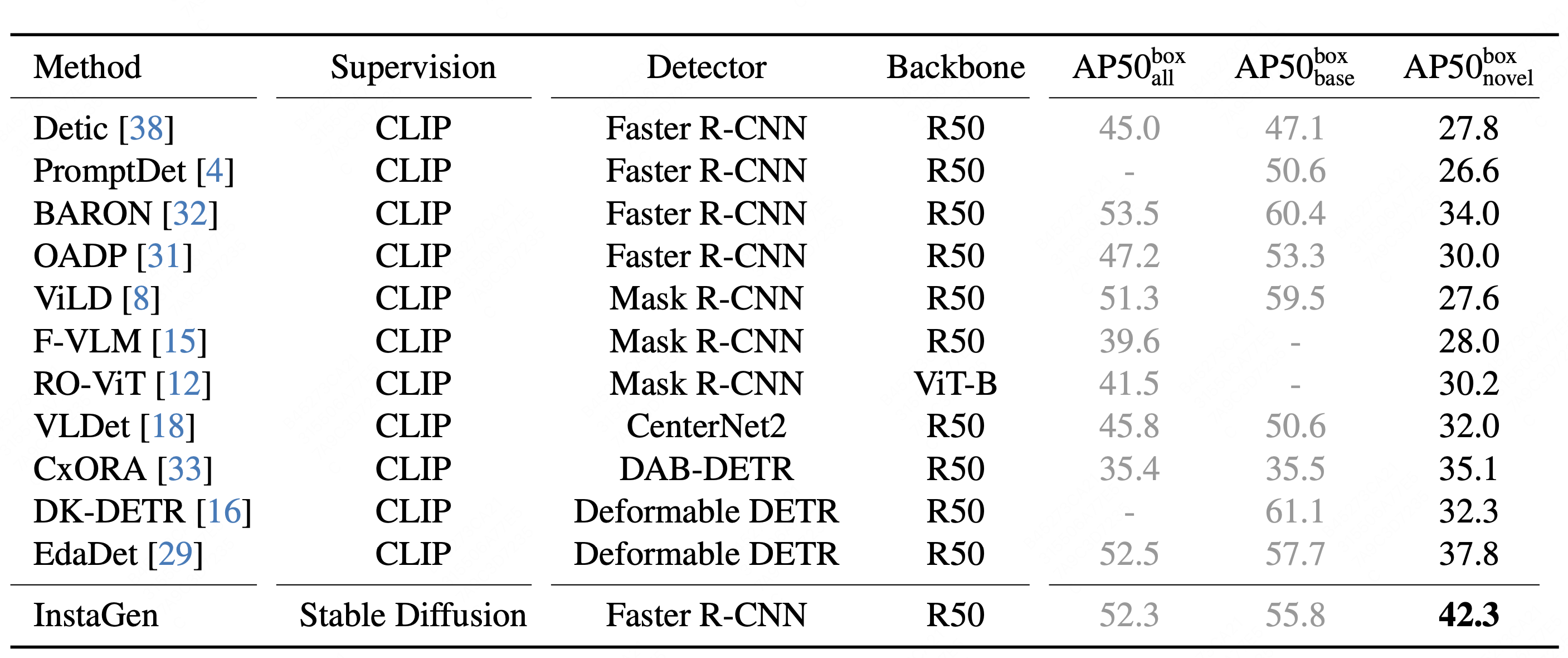
| R1: Results on open-vocabulary COCO benchmark. We evaluate the performance by comparing with existing CLIP-based open-vocabulary object detectors. It is clear that our detector trained on synthetic dataset from InstaGen outperforms existing state-of-the-art approaches significantly, i.e., around 5AP improvement over the second best. |
 |
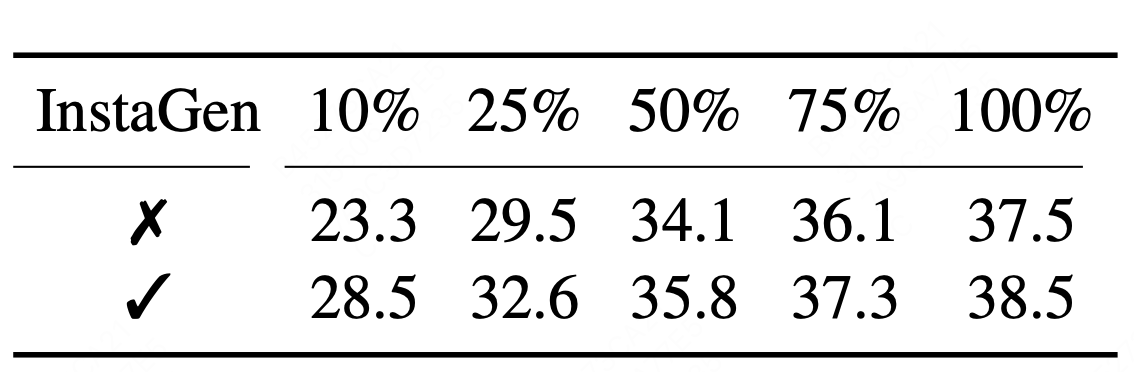
| R2: Results on data-sparse object detection. The Faster R-CNN trained with synthetic images achieves consistent improvement across various real training data budgets. Notably, as the availability of real data becomes sparse, synthetic dataset plays even more important role for performance improvement. For instance, InstaGen improves the detector by 5.2 AP (23.3→28.5 AP) when applied to the 10% COCO training subset. |
 |
| R3: Results on generalizing COCO-base to Object365 and LVIS. InstaGen achieves superior performance in generalization from COCO-base to Object365 and LVIS, when compared to CLIP-based methods. InstaGen possesses the ability to generate images featuring objects of any category without the need for additional datasets, thereby enhancing its versatility across various scenarios. |
 |
|